Evaluation von synthetischer Datengenerierung für die Erkennung von Mikroorganismen
In meinem Bachelorprojekt an der Hochschule Darmstadt habe ich mich mit der Generierung von synthetischen Daten für die Objekterkennung von Mikroorganismen unter dem Mikroskop beschäftigt. Ziel war es, den Mangel an annotierten Trainingsdaten zu überwinden, der häufig in spezialisierten Anwendungsgebieten wie der Mikrobiologie auftritt. Außerdem sollte die Realitätsnähe der synthetischen Daten bewertet werden, um ihre Eignung für den Einsatz in Machine-Learning-Modellen zu prüfen.
Motivation
Die manuelle Annotierung von Mikroskopbildern ist zeitaufwendig und teuer. Besonders im Bereich der Abwasseranalyse, wo Mikroorganismen wie Bärtierchen als Indikatoren dienen, fehlt es an großen, diversifizierten Datensätzen. Hier bietet synthetische Datengenerierung eine effiziente Lösung.
Ansatz: Die “Cut-Paste”-Methode
Der Kern meiner Arbeit ist die Evaluation der sogenannten “Cut-Paste”-Methode. Dabei werden Mikroorganismen aus bestehenden Bildern ausgeschnitten und in verschiedene Hintergründe eingefügt.
Weiterhin wurden verschiedene Blending-Methoden getestet, um die Realitätsnähe der synthetischen Bilder zu erhöhen:
| Alpha Blending | Gaussian Blending | Poisson Blending | Pyramid Blending |
|---|---|---|---|
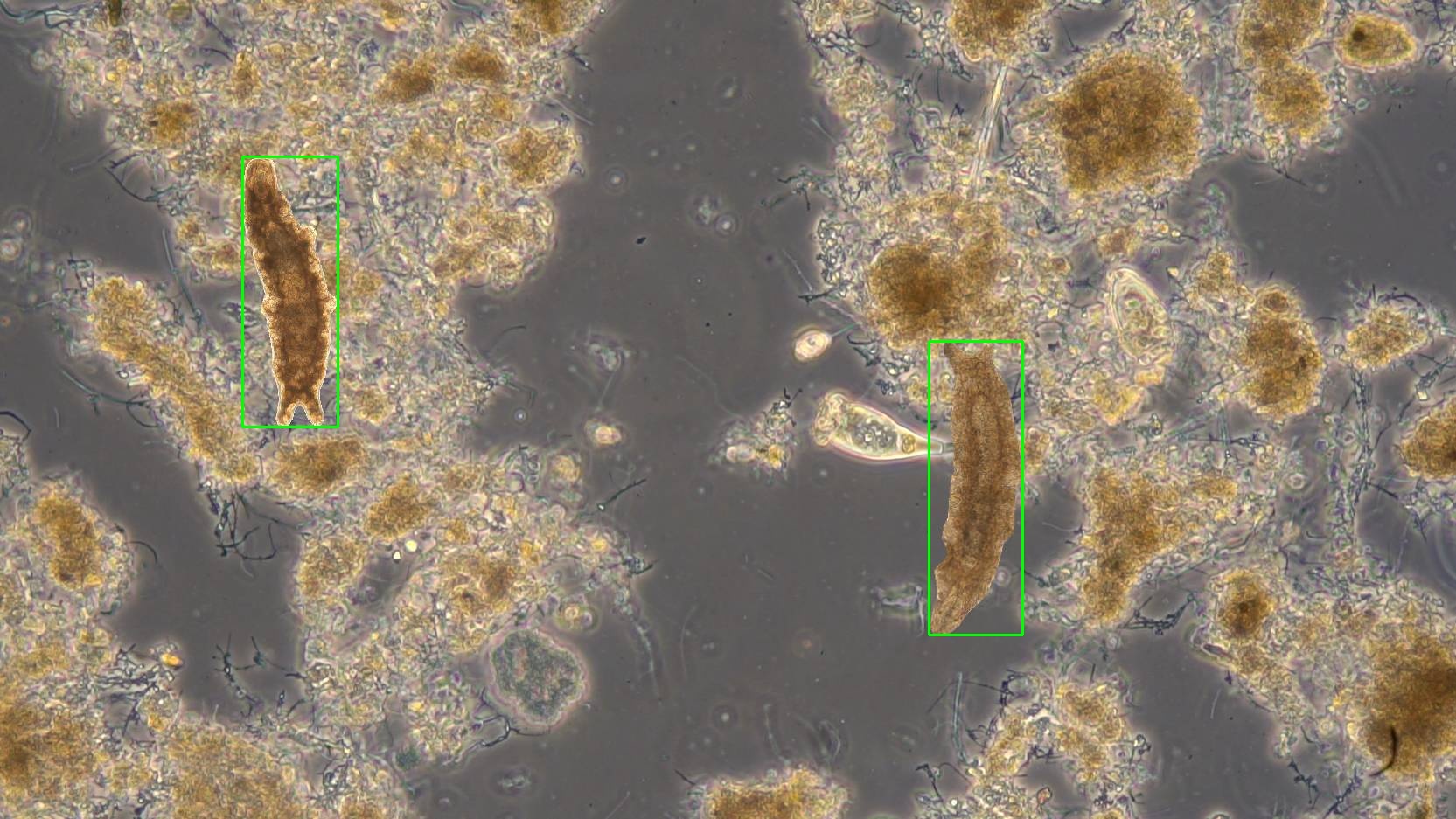 |
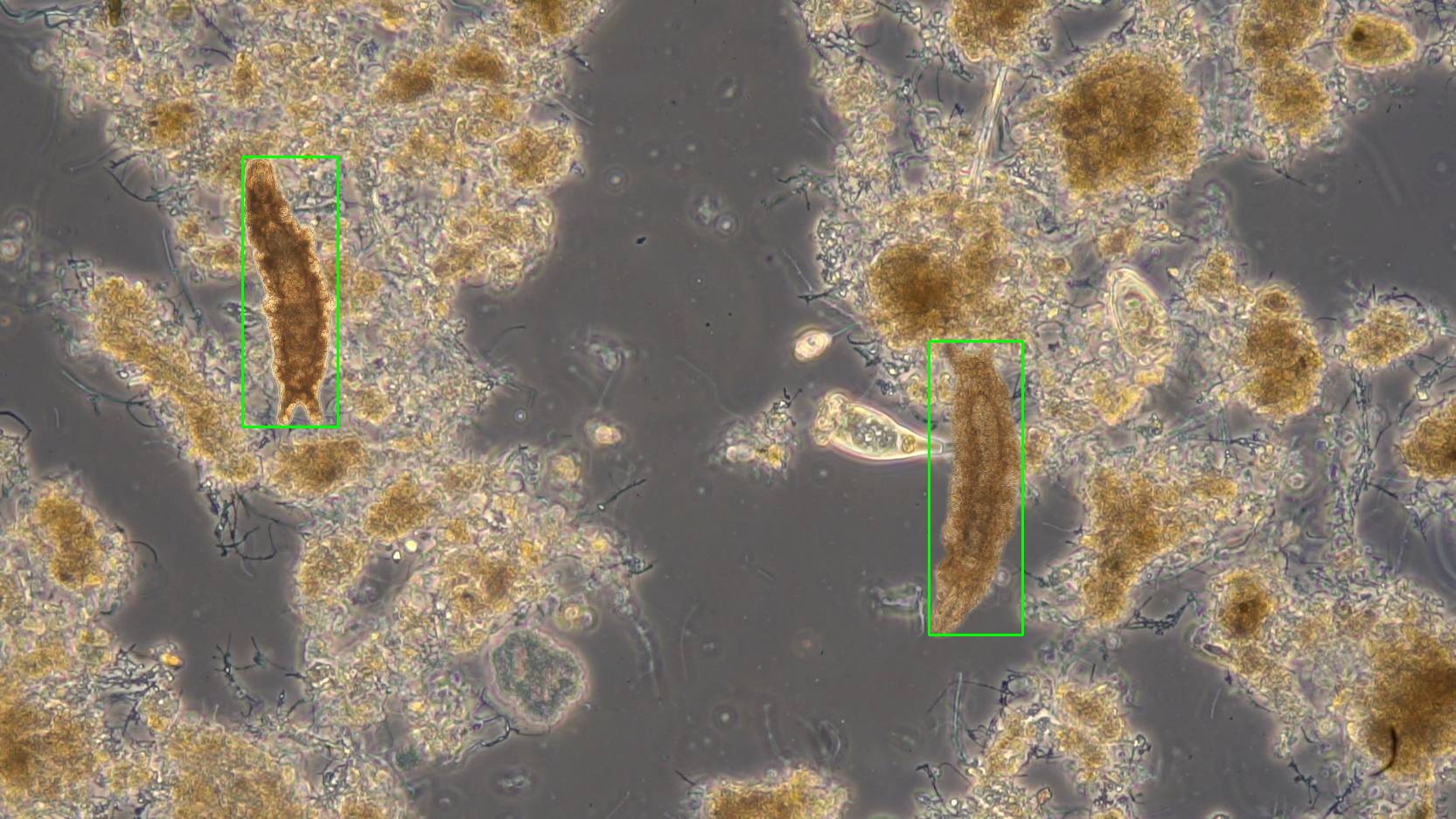 |
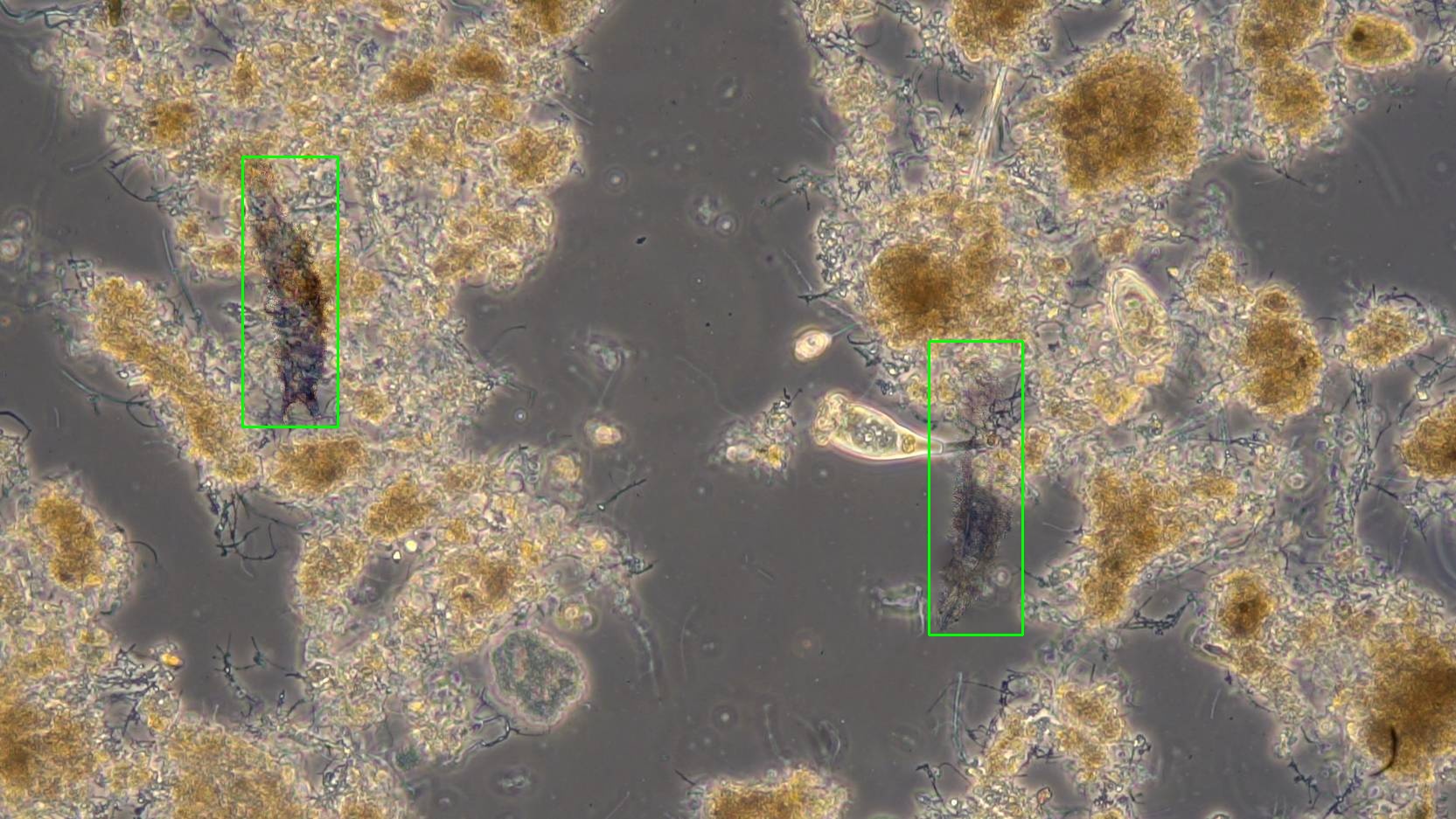 |
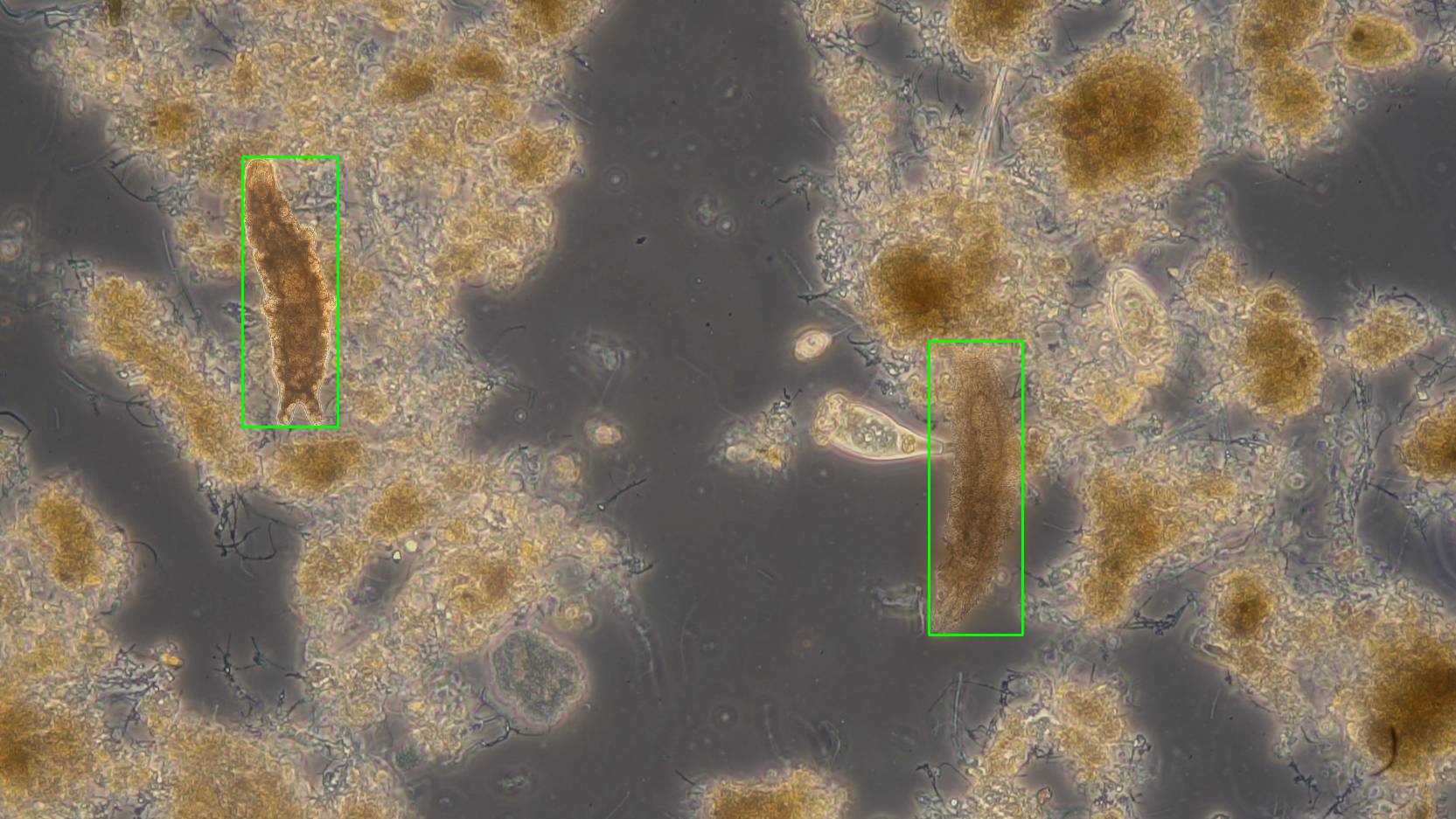 |
Zusätzlich wurde ein Multi-Methoden-Ansatz erprobt, bei dem mehrere Blending-Techniken kombiniert wurden.
Experimentelle Ergebnisse
Durch die Verwendung der synthetischen Datensätze zur Verbesserung eines YOLOv11-Modells für die Objekterkennung ergaben sich folgende Erkenntnisse:
- Pyramid Blending führte zu einer Leistungssteigerung von 0,16 mAP50.
- Kombinierte Blending-Methoden erzielten sogar eine Verbesserung von 0,18 mAP50.
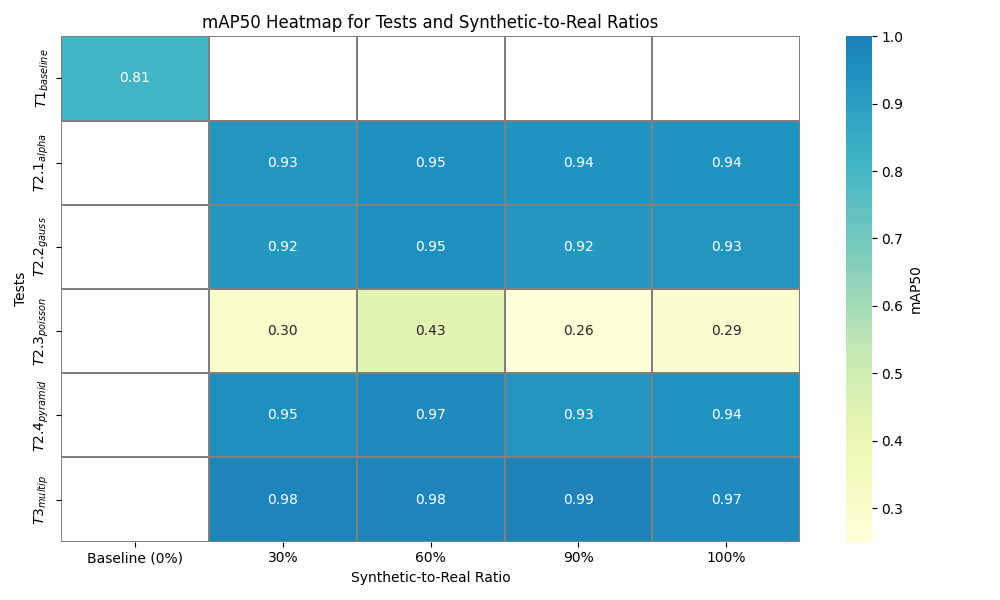
Diese Resultate zeigen, dass synthetische Daten nicht nur den Datensatz erweitern, sondern auch die Robustheit und Generalisierungsfähigkeit des Modells erhöhen.
Bewertung der Realitätsnähe
Um die Ähnlichkeit zwischen synthetischen und realen Daten zu quantifizieren, wurden zwei weitere Metriken verwendet: Diese Metriken messen die Distanz zwischen den Verteilungen von synthetischen und realen Bildern.
- Fréchet Inception Distance (FID)
- CLIP Maximum Mean Discrepancy (CMMD)
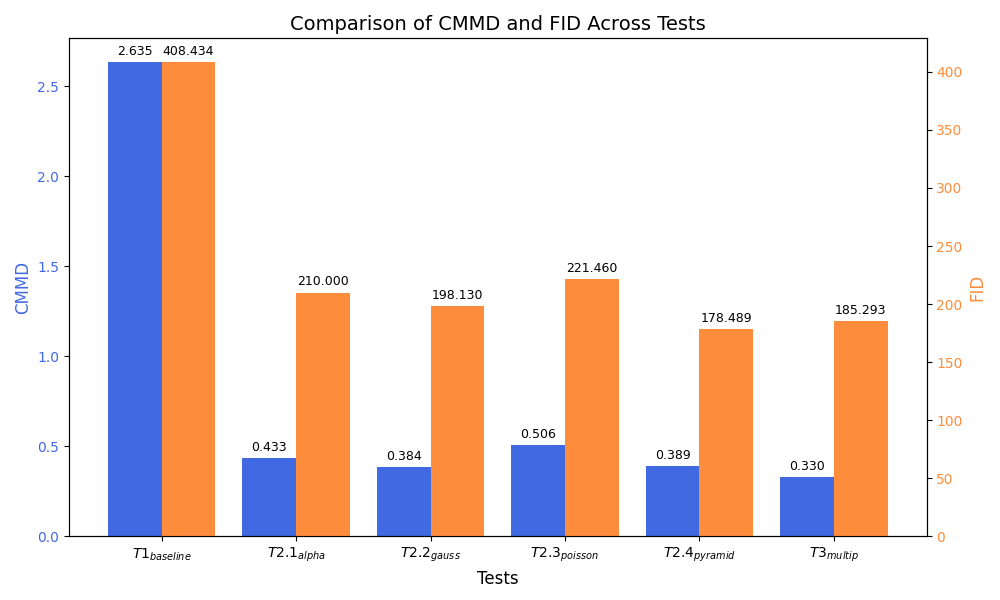 Niedrige Werte deuten auf eine geringe Differenz hin.
Niedrige Werte deuten auf eine geringe Differenz hin.
Beide Metriken zeigten niedrigere Werte für Datensätze, die mit Pyramid Blending oder kombinierten Methoden erzeugt wurden. Das weist auf eine geringere synthetic-to-reality gap hin.
Fazit
Die “Cut-Paste”-Methode in Kombination mit geeigneten Blending-Techniken ist eine vielversprechende Strategie, um qualitativ hochwertige synthetische Trainingsdaten für die Objekterkennung von Mikroorganismen zu erzeugen. Besonders Pyramid Blending und Multi-Methoden-Ansätze liefern dabei die besten Ergebnisse.
Du hast Fragen zu meiner Arbeit oder möchtest mehr über synthetische Datengenerierung erfahren? Schreib mir gerne eine E-Mail oder kontaktiere mich auf LinkedIn.