Build your own machine learning environment with a litte python game
In this chapter we will create our own environment to learn our agent in python. First we will create the basic game. A Pong (bouncing ball with a paddle) game.
The game (game.py)
import turtle as t
import random
ballSpeed = 3
paddleSpeed = 40 # X-direction
allTimes = []
class Game():
def __init__(self):
self.done = False
self.reward = 0
self.hit, self.miss = 0, 0
self.hitsPerGame = 0
# Setup Background
self.win = t.Screen()
self.win.title('Paddle')
self.win.bgcolor('black')
self.win.setup(width=600, height=600)
self.win.tracer(0)
self.win.onkey(self.paddle_right, 'Right')
self.win.onkey(self.paddle_left, 'Left')
self.win.listen()
# Paddle
self.paddle = t.Turtle()
self.paddle.speed(0)
self.paddle.shape('square')
self.paddle.shapesize(stretch_wid=1, stretch_len=6)
self.paddle.color('white')
self.paddle.penup()
self.paddle.goto(0, -275)
# Ball
self.ball = t.Turtle()
self.ball.speed(0)
self.ball.shape('circle')
self.ball.color('red')
self.ball.penup()
# Random ball start position
randomX = random.randint(-290, 290)
self.ball.goto(randomX, 100)
self.ball.dx = ballSpeed
self.ball.dy = -ballSpeed
# Score
self.score = t.Turtle()
self.score.speed(0)
self.score.color('white')
self.score.penup()
self.score.hideturtle()
self.score.goto(0, 250)
self.score.write("Hit: {} Missed: {}".format(self.hit, self.miss), align='center', font=('Courier', 24, 'normal'))
# Hits per game
self.avgTime = 0
self.currHits = t.Turtle()
self.currHits.speed(0)
self.currHits.color('white')
self.currHits.penup()
self.currHits.hideturtle()
self.currHits.goto(0, 225)
self.currHits.write("Hits: {}".format(self.hitsPerGame), align='center', font=('Courier', 24, 'normal'))
def paddle_right(self):
if self.paddle.xcor() < 225:
self.paddle.setx(self.paddle.xcor() + paddleSpeed)
def paddle_left(self):
if self.paddle.xcor() > -225:
self.paddle.setx(self.paddle.xcor() - paddleSpeed)
def run_frame(self, render):
if render:
self.win.update()
# Ball movement
self.ball.setx(self.ball.xcor() + self.ball.dx)
self.ball.sety(self.ball.ycor() + self.ball.dy)
# Border Wall checking
if self.ball.xcor() > 290:
self.ball.setx(290)
self.ball.dx *= -1
if self.ball.xcor() < -290:
self.ball.setx(-290)
self.ball.dx *= -1
if self.ball.ycor() > 290:
self.ball.sety(290)
self.ball.dy *= -1
# Ball Ground checking
if self.ball.ycor() < -290:
self.ball.goto(0, 100)
self.miss += 1
self.score.clear()
self.score.write("Hit: {} Missed: {}".format(self.hit, self.miss), align='center', font=('Courier', 24, 'normal'))
self.reward -= 3
self.done = True
# Ball paddle checking
if abs(self.ball.ycor() + 250) < 10 and abs(self.paddle.xcor() - self.ball.xcor()) < 70:
self.ball.dy = abs(self.ball.dy)
self.hit += 1
self.hitsPerGame += 1
self.score.clear()
self.score.write("Hit: {} Missed: {}".format(self.hit, self.miss), align='center', font=('Courier', 24, 'normal'))
self.reward += 3
def reset(self):
self.done = False
self.paddle.goto(0, -275)
self.hitsPerGame = 0
# Random ball start position
randomX = random.randint(-290, 290)
self.ball.goto(randomX, 100)
# Random ball start direction
randXDir = random.randint(0, 1)
randYDir = random.randint(0, 1)
if randXDir == 0:
self.ball.dx = -ballSpeed
else:
self.ball.dx = ballSpeed
if randYDir == 0:
self.ball.dy = -ballSpeed
else:
self.ball.dy = ballSpeed
return [self.paddle.xcor()*0.01, self.ball.xcor()*0.01, self.ball.ycor()*0.01, self.ball.dx, self.ball.dy]
def step(self, action, render=False):
self.reward = 0
self.done = False
if action == 0:
self.paddle_left()
self.reward -= 0.1
elif action == 2:
self.paddle_right()
self.reward -= 0.1
self.run_frame(render)
self.currHits.clear()
self.currHits.write("Hits: {}".format(self.hitsPerGame), align='center', font=('Courier', 24, 'normal'))
state = [self.paddle.xcor()*0.01, self.ball.xcor()*0.01, self.ball.ycor()*0.01, self.ball.dx, self.ball.dy]
return self.reward, state, self.done
if __name__ == '__main__':
env = Game()
while True:
env.run_frame(True)
if env.done:
env.reset()
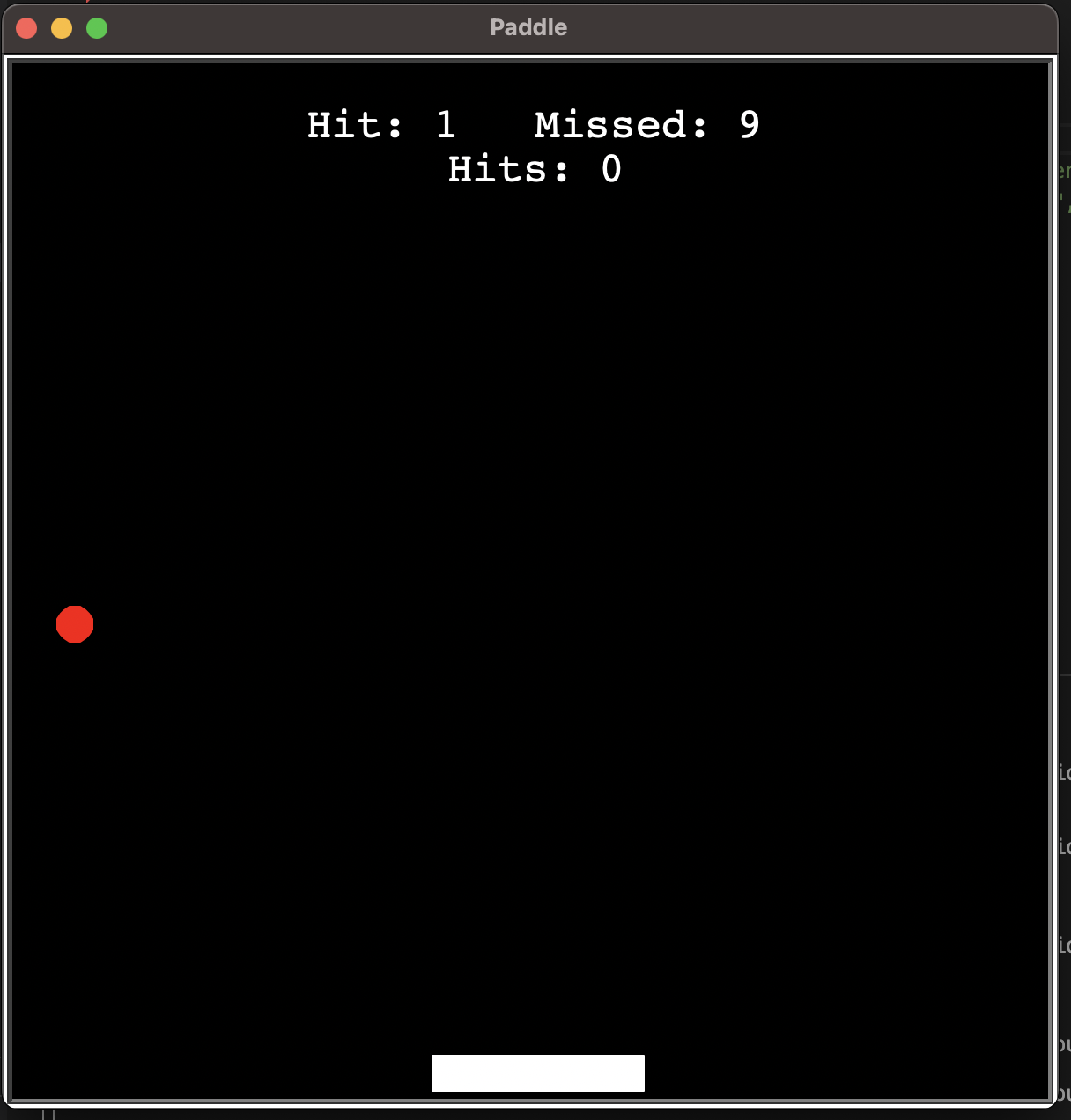
Results
Run the code
python3 game.py
The Agent (agent.py)
Now we create our ml agent, which will play our game.
from time import sleep
from game import Game
import random
import numpy as np
from keras import Sequential
from keras.models import load_model, model_from_json
from collections import deque
from keras.layers import Dense
import matplotlib.pyplot as plt
from keras.optimizers import Adam
# pip3 install tensorflow-macos
env = Game()
np.random.seed(0)
from keras.utils.vis_utils import plot_model
class DQN:
""" Implementation of deep q learning algorithm """
def __init__(self, action_space, state_space):
self.action_space = action_space
self.state_space = state_space
self.epsilon = 1
self.gamma = .95
self.batch_size = 64
self.epsilon_min = .01
self.epsilon_decay = .995
self.learning_rate = 0.001
self.memory = deque(maxlen=100000)
self.model = self.build_model()
def build_model(self):
try:
# load json and create model
json_file = open('model.json', 'r')
print("Loaded model from disk")
sleep(1)
loaded_model_json = json_file.read()
json_file.close()
loaded_model = model_from_json(loaded_model_json)
# load weights into new model
loaded_model.load_weights("model.h5")
loaded_model.compile(loss='mse', optimizer=Adam(lr=self.learning_rate))
return loaded_model
# # return loaded_model
except:
print('No model found - creating new one')
sleep(1)
model = Sequential()
model.add(Dense(64, input_shape=(self.state_space,), activation='relu'))
model.add(Dense(64, activation='relu'))
model.add(Dense(self.action_space, activation='linear'))
model.compile(loss='mse', optimizer=Adam(lr=self.learning_rate))
model.trainable = True
return model
def remember(self, state, action, reward, next_state, done):
self.memory.append((state, action, reward, next_state, done))
def act(self, state):
if np.random.rand() <= self.epsilon:
return random.randrange(self.action_space)
act_values = self.model.predict(state)
# print(act_values)
return np.argmax(act_values[0])
def replay(self):
if len(self.memory) < self.batch_size:
return
minibatch = random.sample(self.memory, self.batch_size)
states = np.array([i[0] for i in minibatch])
actions = np.array([i[1] for i in minibatch])
rewards = np.array([i[2] for i in minibatch])
next_states = np.array([i[3] for i in minibatch])
dones = np.array([i[4] for i in minibatch])
states = np.squeeze(states)
next_states = np.squeeze(next_states)
targets = rewards + self.gamma*(np.amax(self.model.predict_on_batch(next_states), axis=1))*(1-dones)
targets_full = self.model.predict_on_batch(states)
ind = np.array([i for i in range(self.batch_size)])
targets_full[[ind], [actions]] = targets
self.model.fit(states, targets_full, epochs=1, verbose=0)
if self.epsilon > self.epsilon_min:
self.epsilon *= self.epsilon_decay
def train_dqn(episode):
loss = []
action_space = 3
state_space = 5
# max_steps = 1000
RENDER_EVERY = 1
hitsList = []
agent = DQN(action_space, state_space)
for e in range(episode):
state = env.reset()
state = np.reshape(state, (1, state_space))
score = 0
# for i in range(max_steps):
while True:
action = agent.act(state)
reward, next_state, done = env.step(action, e % RENDER_EVERY == 0)
score += reward
next_state = np.reshape(next_state, (1, state_space))
agent.remember(state, action, reward, next_state, done)
state = next_state
agent.replay()
if done:
hitsList.append(env.hitsPerGame)
print("episode: {}/{}, score: {}".format(e, episode, score))
break
loss.append(score)
plt.plot([e for e in range(len(loss))], loss)
plt.title('Loss')
plt.ion()
plt.draw()
plt.pause(0.001)
plt.plot([e for e in range(len(hitsList))], hitsList)
plt.title('Hits till death')
plt.ion()
plt.draw()
plt.pause(0.001)
if(len(loss) % 5 == 0):
# serialize model to JSON
model_json = agent.model.to_json()
with open("model.json", "w") as json_file:
json_file.write(model_json)
# serialize weights to HDF5
agent.model.save_weights("model.h5")
print("Saved model to disk")
plot_model(agent.model, to_file='./dqn_model.png', show_shapes=True)
print("Episode: {}/{}, score: {}".format(e, episode, score))
return loss
if __name__ == '__main__':
ep = 100
loss = train_dqn(ep)
plt.plot([i for i in range(ep)], loss)
plt.xlabel('episodes')
plt.ylabel('reward')
plt.show()
Result
Run the agent and see the result.
python3 agent.py
When we now run the agent.py we see the paddle moving very random, but over time (ca. 50 episodes) we can see the paddle moving planful towards the ball.